
NoSQL
게시:
수정:

NoSQL이란 SQL이 아니라는 명칭에서 느껴지는 오해와 달리 Not-only SQL이라는 뜻으로 ‘SQL뿐만이 아니다’ 라는 뜻으로 Relational 방식과 달리 SQL만을 사용하지 않는 데이터베이스 시스템을 말한다.[1] 엄격한 2차원 매트릭스인 Relational Database 같은 정보 구조가 아닌 데이터(Key-Value, JSON, XML, Graph 등)를 처리하기 위하여 주로 사용한다.
분산 환경(Cluster)에서 실행할 목적으로 만들어진 경우가 많기 때문에 Relational 모델을 사용하지 않으며 대부분 오픈 소스이다. 21세기 이후에 개발된 시스템만을 NoSQL이라 칭하므로 유사한 목적과 구조를 갖지만 과거에 개발된 Data warehouse(OLAP)은 NoSQL에 해당하지 않는다.
등장 배경
새로운 웹 환경과 빅 데이터(Big-data)가 등장하면서 RDBMS에서 처리하기 어려운 새로운 요구사항이 발생하였다.
데이터와 트래픽이 급격히 증가 함에 따라 데이터 크기가 하나의 시스템에서 감당하기 어려운 크기(Big data)가 되었고, 하나의 시스템이 감당할 수 없는 동시 사용자 수를 요구하게 되면서 System scalability가 슈퍼 컴퓨터로도 감당이 안되는[2] 수준으로 커졌다.
또한 빅 데이터의 많은 부분이 Document(Semi-structured data)로 구성됨에 따라 고정된 스키마(Schema)를 갖지 않고 스키마로부터 자유로운(Schema-free) 데이터. 즉, 비정형 데이터 형태를 요구되게 되었으며, 일단 한 번 Write되면 거의 수정하는 경우가 없고 대부분 Read만 수행되는 트랜잭션(Transaction)이 거의 필요없는 서비스가 등장하였다.
이와 같은 요구사항으로 Semi-structured data[3]를 대량으로 저장하고 관리할 수 있으면서 완전히 Consistency 하진 않은, 어느 정도 신뢰성을 갖춘 시스템이 요구되어 NoSQL이 등장하게 되었다.
아직 NoSQL에 대한 표준은 없지만 한 마디로 NoSQL은 비정형적인 대량의 데이터 환경에 적합하도록 전통적인 RDBMS의 엄격한 Requirements를 완화시켜서 만든 실용적인 데이터베이스 솔루션이라고 할 수 있다.
“The whole point of seeking alternatives(to RDB Management Systems) is that you need to solve a problem that relational databases are a bad fit for.”
Eric Evans
유형 및 유형별 특징
데이터 표현 방법과 솔루션만큼 종류도 다양하지만 크게 Key-Value, Column-Family, Graph, Document 이렇게 4가지로 구분한다.
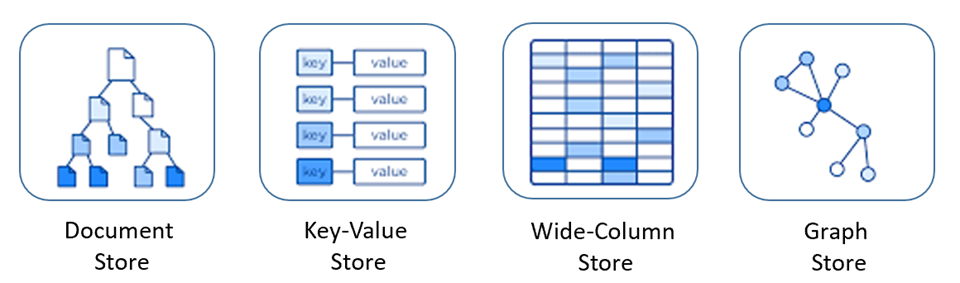
출처: 마이크로소프트. ‘관계형 마이닝 모델과 NoSQL 데이터 비교’. https://docs.microsoft.com/ko-kr/dotnet/architecture/cloud-native/relational-vs-nosql-data
1. Key-Value Store
키와 값만을 매칭하여 빠르게 저장하고 처리하는 단순한 시스템이다.
Key-Value Store는 두 개의 열(Key, Value)과 간단한 인터페이스(Put, Get, Delete)가 있는 테이블이다. 빠르고 쉽게 확장 가능하며 많은 양의 데이터를 빠르게 저장하고 처리할 수 있다. 다만, Joins이 없으며 Subset 쿼리가 없다. 전통적인 Relational 모델은 결과로 언제나 집합(Tuple)을 반환하지만 Key-Value Model에은 집합에 대한 개념이 아예 없다. 단지 단일 Item을 반환할 뿐이다.

특징
- Key는 불투명한 데이터(Blob)에 접근하는 데 사용된다. 즉, 시스템은 Blob에 어떠한 데이터가 들어있는지 알지 못 한다.
- Value는 모든 Data type을 포함할 수 있다. (e.g. Images, Video)
- Scalable하다. 크기가 아무리 커도 비슷한 성능을 낸다.
- API가 심플(Put, Get, Delete)하다.
- 모든 쿼리는 단일 항목을 반환한다. 즉, Key-Value Store는 Dictionary와 같다.
- 콘텐츠 기반으로 쿼리할 수 없다. 어떠한 Value를 가진 값들을 찾는 쿼리를 수행할 수 없다.
솔루션 종류
- Berkley DB
- Riak
- Redis
- Memcached
- AWS DynamoDB
2. Column-Family(Wide column) Store
Null 값이 제한되는(어쩌다 한 번 나와야 하는) RDBMS와 달리 빈 값(null)이 많은 하나의 큰 테이블이다. 유연한 스키마를 위한 모델이자 빅 데이터를 위한 모델이다.
Row, Column family 및 Column name을 포함[5]한 테이블로 Column-family는 명칭의 뜻 그대로 속성(Column)의 Group을 의미하며 Column(family)에 Nested된 Column 그룹이다.
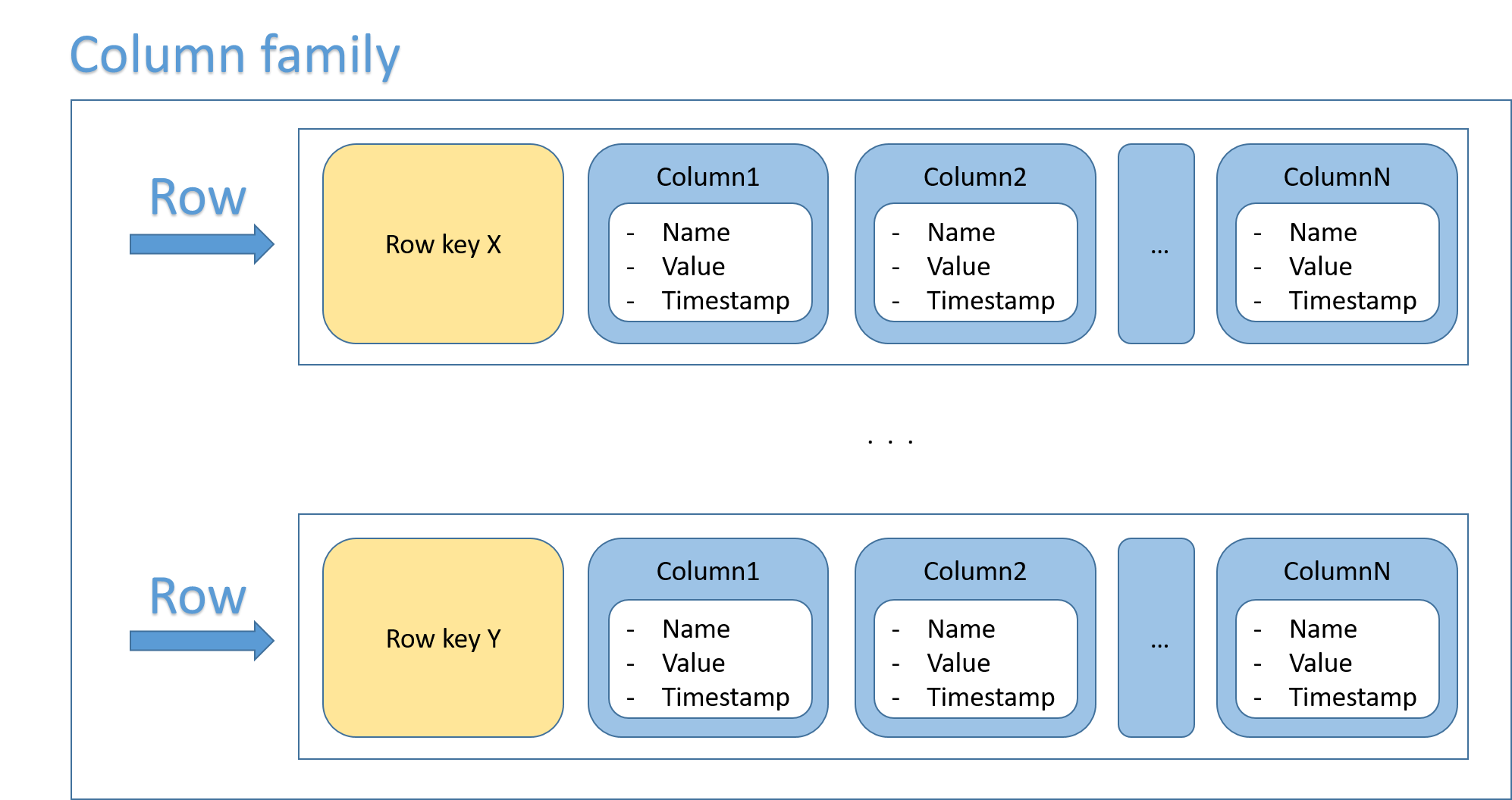
단순 비교해서는 안 되겠지만 형태에 국한시켜 생각했을 때 Row를 수백만 개 가질 수 있는 RDBMS 테이블을 90° 돌려서 보았을 때의 형태가 Column-family라고 생각하면 이해하기 쉽다. RDMBS는 Row를 수직적으로 늘리지만 Column-family는 Column(속성)을 수평적으로 늘리는 형태이다.
속성을 수평적으로 무한히 확대(Scale-out)할 수 있기 때문에 변동성이 큰 데이터 세트(빅 데이터)에 최적화된 모델이며 실제로 MapReduce와 긴밀하게 결합하여 동작한다. 이러한 특성으로 인하여 하나의 행은 수백만 개의 Column을 가질 수 있지만 데이터는 희소(Sparse)할 수 있다.[6]
Row, Column(Column-family)에 대해 쿼리가 가능하고 Column-family를 사용하면 특정 속성(Attribute)이 있는 모든 Column에 대해서 쿼리할 수 있지만 Key-Value 모델과 마찬가지로 Blob의 콘텐츠 기반 쿼리 수행은 불가능하다.
특징
- Key에는 Row, Column family 및 Column name이 포함된다.
- 테이블 생성 시 Column family가 생성된다.
- Alter table을 수행하지 않고 Column을 삽입할 수 있다.
- MapReduce와 긴밀하게 결합하여 동작한다.
- 변동성이 큰 데이터 세트에 이상적이다.
- Scale-out, Version 관리(Timestamp)에 용이
- Row, Column-family 및 Column name에 대해 쿼리 수행이 가능하다.
- Column-family로 특정 속성이 있는 모든 Column을 쿼리할 수 있다.
- Blob 컨텐츠 기반 쿼리는 불가능하다.
- Joins에 최적화되지 않은 구조이다.
- Row 및 Column에 대한 디자인이 중요하다.
솔루션 종류
- Hadoop HBase
- Cassandra
- Google Bigtable
- Hypertable
3. Graph Store
각 노드를 관계로 연결한 모델로 인간에게 가장 자연스러운 모델이자 진정한 빅데이터에 가까운 모델이다. 자료구조의 그래프 데이터 구조(Graph data structure)를 그대로 데이터베이스로 저장하는 모델이다.
실제로 쿼리도 그래프 순회(Traversals)이며, 따라서 쿼리 프로세스 자체가 복잡하고 부하가 크다. 또한 그래프 구조이기 때문에 네트워크 하나를 순회하는 것 자체가 RDBMS의 Joins와 같다.
데이터 간의 관계 및 관계 유형이 핵심적일 때 이상적이다.
(e.g. 소셜 네트워크, 추론 엔진, 패턴 인식, Open-linked data[7])
특징
- 빠른 네트워크 검색
- 연결된 공개 데이터(Open-linked data) 작업에 사용
- 그래프가 RAM에 맞지 않을 때 확장성 저하
- 특수 쿼리 언어(RDF[8] users SPARQL) 사용
솔루션 종류
- Neo4j
- AllegoGraph
- Bigdata triple store
- InfiniteGraph
- StarDog
4. Document Store
애플리케이션에서 지원하는 Document를 중간에 매핑없이 그대로 데이터베이스에 저장하는 것을 말한다. 여기서 Document란 중첩된 계층의 데이터를 의미한다. 즉, 단순히 키워드가 나열되어 있는 Set of keywords 형태가 아니라 키워드들이 나름의 Organized되어 Struct를 갖는 형태를 말한다. (e.g. XML, JSON)

예를 들어 웹 문서를 계층적 특성을 살려서 RDBMS에 저장하고자 하면, 문서를 구조적으로 쪼개서(Shredding[9]) 관계형 테이블에 맞도록 매핑하여 저장해야 하지만, Document store는 그대로 저장하면 된다. 따라서 ORM(Object-Relational Mapping) Layer가 필요 없어진다.
이와 같이 계층적 구조는 유지하면서 ORM이 사라지면서 쿼리에 대한 장점은 살리다보니(게다가 빠르다) 어플리케이션 구축의 복잡성이 해소된다. 또한 데이터가 데이터베이스에 들어올 때 자동으로 인덱싱 방법을 결정하므로 DDL(Data Definition Language)과 선행 논리적 데이터 모델링도 필요없어지게 된다.
다만 구현이 복잡하고 자체적인 Query Language 외의 SQL과는 호환되지 않는다는 단점이 있다.
특징
- 논리적 데이터(Document)를 단일 데이터 단위로 저장한다.
- JSON 또는 XML 형식을 사용하여 문서(Document)를 저장한다.
- 문서의 모든 항목을 쿼리할 수 있다.
- 하위 트리 및 속성을 XQuery[10] 또는 기타 문서 Query Language로 쿼리할 수 있다.
- 수백만 개의 레코드를 검색하는데 1초 미만의 응답 시간을 갖는다.
- ORM(Object-Relational Mapping) 레이어가 없으므로 검색에 이상적이다.
- 데이터를 테이블에 맞춰서 Shredding하지 않는다.
- 애자일하게 빠르게 개발 가능하다.
- ACID 트랜잭션 지원을 포함한다.
- 데이터가 DB에 로드될 때 인덱싱하는 방법을 자동으로 결정한다.
- 데이터 구조에 대한 사전지식이 불필요하다.
- 선행 논리적 데이터 모델링이 불필요하다.
- 새로운 데이터 요소를 추가하거나 변경해도 중단되지 않는다.
솔루션 종류
- Marklogic
- MongoDB
- Couchbase
- CouchDB
- eXist-db
Hybrid Architecture
현실에서 대부분의 구현은 NoSQL의 일부 조합을 사용한다.
- 데이터에 대한 문서 저장소 사용
- 이미지/pdf/바이너리 저장을 위해 AWS S3 사용
- 문서 색인 저장소에 Apache Lucene 사용
- 실시간 인덱스 및 집계 생성 및 유지 관리를 위해 MapReduce 사용
- 합계 및 합계 보고에 OLAP 사용 등
Reference
용환승, “NoSQL Database Patterns”. KOCW. 2014년. video, http://www.kocw.net/home/cview.do?lid=be49d0e757161b3e
용환승, “NoSQL Database Patterns”. KOCW. 2014년. video, http://www.kocw.net/home/cview.do?lid=608d12c30ff79fe0
각주
1: No RDBMS를 의미하지 않는 이유는 RDMBS와 유사한 NoSQL 솔루션도
존재하고 SQL 호환을 지원하는 NoSQL 솔루션도 존재하기 때문이다.
2: 장비 성능 향상(Scale-up)을 무한히 시킬 수 있다는 가정하에
끝없이 Scale-up을 하면 빅 데이터를 처리할 수 있으나 그만큼 Cost도 기하급수적으로 증가하기 때문에
현실성 없는 이야기이다.
3: Twitter, On-line game의 User log 등.
4: Structured data: Relational, Unstructured data: Text.
5: Key에는 Timestamp도 포함되어 있는데 이는 버전을 관리하기 위하여 사용된다. 또한
Bigtable 시스템(Made by Google)에는 행 및 열 ID뿐 아니라 기타 속성을 포함하는 키가 있다.
6: 대부분의 셀에 값이 없다. 이처럼 속성(Column)만 수백만 개 있고,
값이 Sparse하게 들어 있는 Table을 인간이 분석하는 것은 거의 불가능에 가깝다고 볼 수 있다.
7: 인터넷의 모든 Meta data를 표준화시킨 형태. 두 개의 컨셉간의
관계를 맺어주는 Subject・Object・Relation의 Triple 형태로 모든 정보를 표현한다.
8: 전세계의 모든 데이터를 개방된 링크로 표준화하여 엮은 데이터.
9: Document 형태의 데이터를 저장하기 위하여 분해 및 관계형 테이블에
맞도록 매핑하는 것
10: XML 데이터에 대한 표준 Query Language
댓글남기기