
CPU 스케줄링 3.
게시:
본 포스팅에서는 큐(Queue)가 여러 개인 경우와 다중 프로세서(CPU)・스레드(Thread) 스케줄링, 실시간(Real-time) 스케줄링에 대한 내용을 다룬다.
멀티레벨 큐(Multilevel Queue)
CPU를 기다리는 레디 큐(Ready Queue)가 한 줄이 아닌 여러 줄인 경우 각 큐에는 우선 순위가 존재한다. 아래 이미지는 멀티레벨 큐의 한 예시이다.
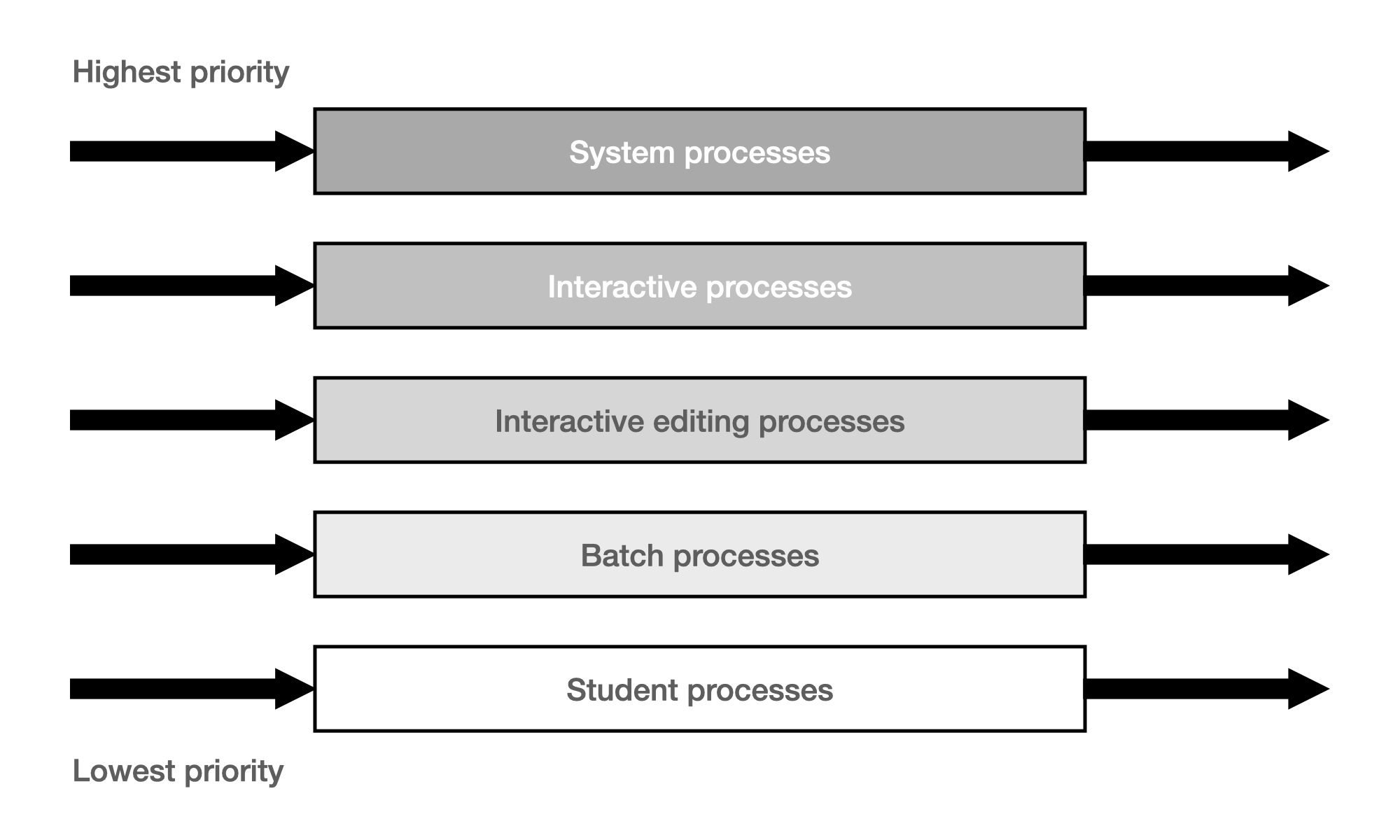
(단일 CPU인 경우) CPU를 쓸 수 있는 프로세스는 어느 한 줄에서 나온 Job뿐이므로 우선 순위가 낮은 Queue에서는 Starvation 현상이 발생할 수 있다.
각 큐는 독립적인 스케줄링 알고리즘을 갖는다. 따라서 Starvation을 최소화하기 위하여 각 프로세스를 어떤 큐에 넣을 것인지와 개별 큐에 어떤 알고리즘을 선택할 것인지 결정해야 한다.
인터랙티브(Interactive)한 Job과 그렇지 않은 Batch job이 있는 경우를 가정하자. 인터랙티브한 Job은 CPU 사용시간이 짧은 특징이 있고 빠른 응답속도를 갖길 원한다. 반면 Batch job은 CPU 사용시간이 길고 사람과 상호작용할 필요가 없어 굳이 빠른 응답을 주지 않아도 된다.
이와 같은 경우 인터랙티브한 Job은 빠른 응답을 위하여 우선 순위가 높은 큐에 삽입하고 해당 큐에는 RR 알고리즘을 적용하고 그렇지 않은 Job은 낮은 우선 순위 큐에 삽입하고 CPU를 오래 쓸 수 있는 FCFS 알고리즘을 적용하는 것이 적절하다.
인터랙티브한 Job vs Batch Job
| 구분 | Interactive Job | Batch-no human interaction |
|---|---|---|
| Priority | Foreground | Background |
| Algorithm | RR(Round Robin) | FCFS(First-Come First-Served |
위 예시와 같이 큐와 알고리즘을 선택한 경우에도 우선 순위를 엄격하게 지키는 경우(Fixed priority scheduling) Starvation이 발생할 수 있기 때문에 각 큐에 적절한 비율(Ex: Foreground 80%, Background 20%)로 CPU time을 할당(Time slice)해야 한다.
멀티레벨 피드백 큐(Multilevel Feedback Queue)
여러 개의 레디 큐를 두면서 경우에 따라서 프로세스가 큐를 옮겨갈 수 있는 방식이다. 멀티레벨 큐를 타임 슬라이스하여 적절히 CPU time을 분배한다고 하더라도 우선 순위가 변경되지 않기 때문에 우선 순위가 낮은 큐에 있는 프로세스는 영원히 실행되지 않는 Starvation 문제가 발생할 수 있다.
멀티레벨 큐에서는 프로세스가 다른 큐로 이동 가능하도록 하여 이러한 문제를 해결한다.
멀티레벨 피드백 큐 스케줄러를 정의하는 매개변수(Parameters)
멀티레벨 피드백 큐의 매개변수는 어찌보면 해당 알고리즘을 쓰기 위하여 해결해야할 숙제와 같다.
- Queue의 수
- 각 큐의 스케줄링 알고리즘
- 프로세스를 상위 큐로 보내는 기준
- 프로세스를 하위 큐로 내쫓는 기준
- 프로세스가 CPU 서비스를 받으려 할 때 들어갈 큐를 결정하는 기준
일반적인 멀티레벨 피드백 큐
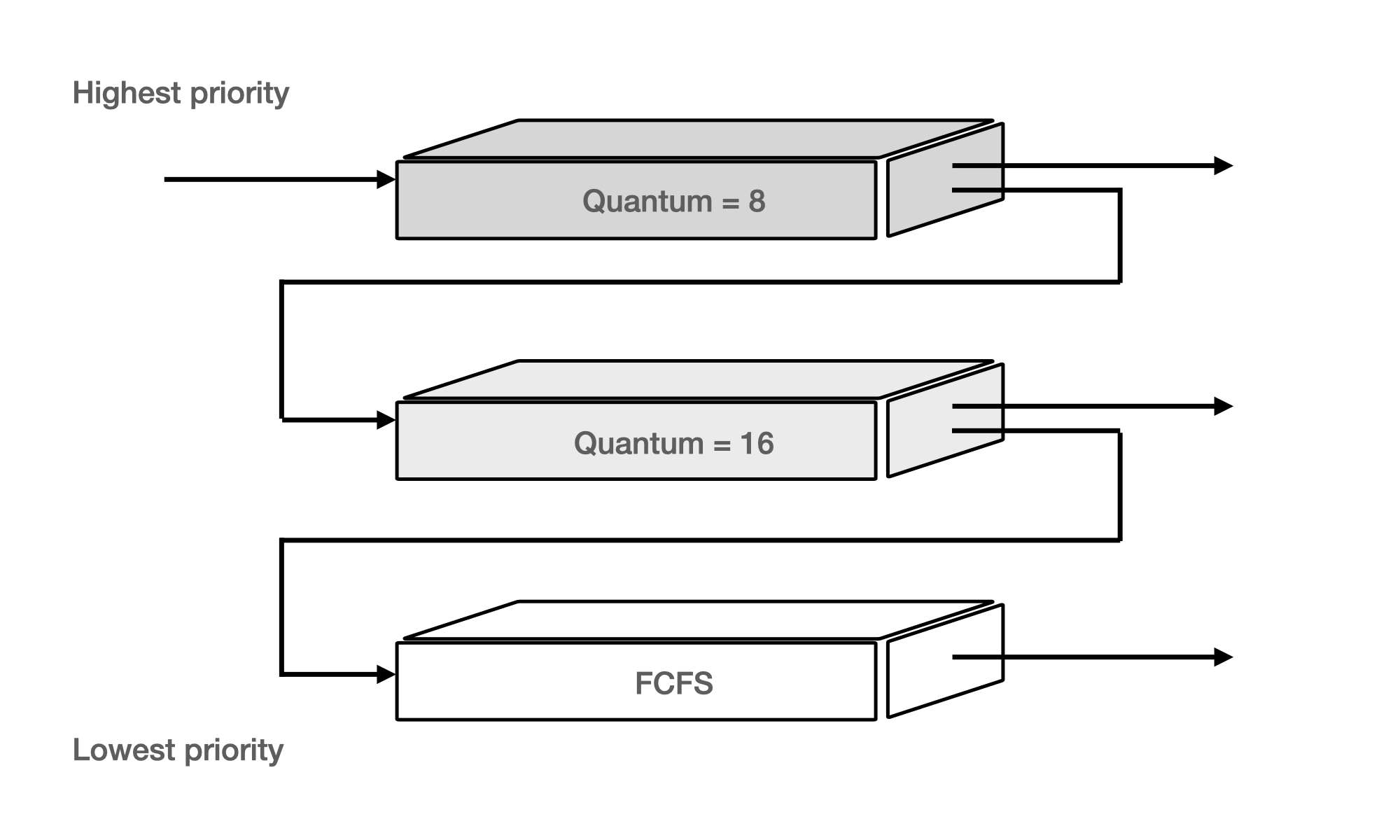
멀티레벨 피드백 큐는 보통 다음과 같이 운영된다. 빠른 이해를 위하여 아래의 이미지를 참고하라.
- 큐의 우선 순위가 높을수록 타임 퀀텀(Time quantum)이 짧고 낮아질수록 길어진다.
- 큐의 우선 순위가 높은 큐는 RR 알고리즘이고 낮은 큐는 FCFS이다.
- 처음 Arrived한 프로세스는 우선 순위가 제일 높은 큐에 삽입한다.
- 각 큐의 타임 퀀텀 내에 처리되지 못한 프로세스는 우선 순위가 한 단계씩 낮아진다.
- 즉, CPU 사용시간이 짧은 프로세스에게 우선권을 많이 주는 스케줄링 방식이다.
Multiple Processor Scheduling
CPU가 여러 개인 경우 스케줄링은 더욱 복잡해진다. 각 케이스별 특징만 간단히 알아보자.
Homogeneous Process인 경우
- Queue에 한 줄로 세워서 각 프로세스가 알아서 꺼내가게 할 수 있다.
- 반대로 특정 프로세스를 특정 프로세서(CPU)가 꼭 실행해야 하는 경우엔 문제가 복잡해진다.
Load sharing
- 특정 프로세서(CPU)만 일하고 나머지 프로세서(CPU)는 노는 상황이 발생하지 않아야 한다.
- 일부 프로세서(CPU)에 Job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘이 필요하다.
Symmetric Multiprocessing (SMP)
- 모든 프로세서(CPU)가 대등한 것을 말한다. 각 프로세서가 각자 알아서 스케줄링을 결정한다.
Asymmetric Multiprocessing
- 하나의 프로세서(CPU)가 시스템 데이터 접근과 공유를 책임지는 전체적인 컨트롤을 담당하고
- 나머지 프로세서(CPU)는 거기에 따르는 것이다.
Real-time Scheduling
Real-time Job을 프로세서(CPU)에서 데드라인(Deadline)안에 끝내는 것을 보장하는 스케줄링이다. 그때 그때 스케줄링하기보다는 보통 미리 스케줄링을 해놓는다.
Hard real-time systems
Hard real-time task는 정해진 시간 안에 반드시 끝내도록 스케줄링해야 한다.
군사, 위성, 시간계산, 우주과학 계산 등이 이에 해당한다.
Soft real-time systems
Soft real-time task는 데드라인은 존재하지만 반드시 지켜야 하는 것은 아니다.
일반 프로세스에 비해 높은 Priority를 갖도록 해야 한다.
Thread Scheduling
Local Scheduling
유저 레벨 스레드(User level thread)에서는 사용자 수준의 스레드 라이브러리에 의해 어떤 스레드를 스케줄링할지 결정한다.
유저 레벨 스레드는 운영체제가 스레드의 존재를 모른다. 따라서 운영체제의 입장에서는 단지 해당 프로세스에게 CPU 줄지 말지 결정할 뿐이고, 프로세스에게 CPU가 왔을 때 어떤 스레드에 CPU를 줄지는 프로세스 내부에서 결정한다.
Global Scheduling
커널 레벨 스레드(Kernel level thread)에서는 일반 프로세스와 마찬가지로 커널의 단기 스케줄러가 어떤 스레드를 스케줄할지 결정한다.
커널 레벨 스레드는 애초에 운영체제가 스레드의 존재를 알기 때문에 일반 프로세스 스케줄링 하듯 운영체제가 나름의 알고리즘에 근거해서 어떤 스레드에 CPU를 줄 것인지 결정한다.
Reference
반효경, “반효경 [운영체제] 11. CPU Scheduling 2 / Process Synchronization 1” KOCW. 2014년 4월 1일. video, http://www.kocw.net/home/cview.do?lid=aa53d6aa576466ee
OS 시리즈 모두보기 (펼치기)
- OS 개요
- OS System Structure & Program Execution. Part 1.
- OS System Structure & Program Execution. Part 2.
- 프로세스(Process) Part 1.
- 프로세스(Process) Part 2.
- Process Management(Creation, Execution, Wait & Exit) 1.
- Process Management(Cooperating Process) 2.
- CPU 스케줄링 1.
- CPU 스케줄링 2.
- (현재글) CPU 스케줄링 3.
- Process Synchronization 1.
- Process Synchronization 2.
- Process Synchronization 3.
- Process Synchronization 4.
- Process Synchronization 5.
- Deadlock
- Memory Management 1.
- Memory Management 2.
댓글남기기