
빅오(Big-O) 표기법
게시:
본 포스팅은 빅오(Big-O) 표기법이 필요한 이유를 알고리즘 성능 분석 측면으로부터 점근적 표기법 필요성까지 순차적으로 접근하여 빅오(O), 빅오메가(Ω), 빅세타(Θ) 표기법에 대한 내용까지 다룬다. 다만 알고리즘 성능 척도로 주로 시간 복잡도를 활용하기 때문에 공간 복잡도는 다루지 않는다.
알고리즘의 분석
알고리즘 분석은 정확도에 대한 정확성 분석[1]과 효율성에 대한 성능 분석[2]으로 나눌 수 있다. 성능 분석은 다시 시간(속도)적인 측면과 공간(메모리)적인 측면으로 구분할 수 있다.
이것을 시간적 성능, 공간적 성능이라 칭하고 싶으나 성능(Performance)은 컴퓨터 시스템의 사양이나 프로그래밍 언어에 따라 수준의 차이가 나기 때문에 일정하지 않다. 따라서 이러한 조건에 관계없이 항상 일정한 기준으로 분석하기 위하여 복잡도(Complexity)라는 용어를 사용한다.
복잡도(Complexity)
입력 크기에 따른 단위 연산의 실행 횟수 또는 사용공간이 얼마나 차지하는지를 나타내는 것으로 시간 복잡도(Time complexity)와 공간 복잡도(Space complexity)로 구분할 수 있다.
극단적으로 최소한의 메모리를 사용(공간 복잡도↓)하여 문제를 해결하면 연산의 횟수가 증가(시간 복잡도↑) 하고, 많은 주소공간을 사용(공간 복잡도↑)하면서 효율적으로 문제를 해결하면 연산의 횟수가 감소(시간 복잡도↓)한다. 즉, 시간 복잡도와 공간 복잡도는 트레이드 오프(Trade-off) 관계다.
시간 복잡도(Time Complexity)
알고리즘을 수행하는 데 걸리는 시간을 설명하는 계산 복잡도(Computational complexity)를 말한다. 알고리즘 성능을 나타낼 때는 시간 복잡도를 사용한다.
입력 크기에 따른 단위 연산의 실행 횟수를 세는 것으로 나타낸다. 입력크기 n이 주어지면 단위 연산을 몇 번 하는지 함수로 표현한다. 여기서 주의할 점은 명령의 횟수를 세는 것이 아니라 단위 연산(Basic operation)의 횟수를 센다는 점이다.
- 단위 연산: 알고리즘 실행의 기본이 되는 명령어들의 집합
- 입력 크기: 문제가 가진 매개변수. 즉, 입력 데이터의 크기
알고리즘은 입력 사례에 따라서 시간 복잡도가 일정한 알고리즘이 있고 그렇지 않은 알고리즘이 있다. 다음 2개의 알고리즘 예시를 통하여 입력 사례별 시간 복잡도 형태의 차이점에 대하여 알아보자.
버블 정렬(Bubble sort, exchange sort)
def bubble_sort(lst: list):
for i in range(n-1):
for j in range(i+1, 1):
if (lst[i] > lst[j]): # Basic operation
lst[i], lst[j] = lst[i], lst[j]
- 단위 연산:
lst[i]와lst[j]의 비교 연산 - 입력 크기: 정렬된 리스트
lst의 원소 개수
for-j는 i에 따라 i-1번부터 1번까지 실행되므로 시간 복잡도를 다음과 같이 나타낼 수 있다.
버블 정렬은 이미 정렬된 상태의 리스트가 주어진다고 하더라도 모든 lst[i]를 lst[j]와 lst의
크기만큼 비교해야 하기 때문에 어떠한 입력 사례에도 일정한 복잡도를 갖는다는 것을 알 수 있다.
순차 탐색(Linear search, Sequential search)
def linear_search(lst: list, x: int, n: int) -> int:
for i in lst:
if (i == x) : # Basic operation
return i
- 단위 연산: 리스트
lst의 원소를 찾는 값x와 비교하는 연산 - 입력 크기: 리스트
lst의 원소의 개수n
순차 탐색은 운이 좋아서 조회를 시작 하자마자 x를 찾는 경우도 있을 수 있고, 리스트 끝에 x가 있어서
모든 리스트를 탐색을 해야할 수도 있다. 예를 들어 리스트 lst = [12, 15, 7, 34, 45, 6]인
경우 x = 7이면 3회, x = 12면 1회, x = 6이면 6회 단위 연산을 수행해야 할 것이다.
즉, 운이 좋아서 시작 하자마자 x를 찾는 경우 단 한 번의 단위 연산만 수행하였기 때문에 시간 복잡도
\(Best(n) = 1\)이 되지만, 리스트의 끝에 x가 있는 경우 모두 비교해야 하기 때문에 시간 복잡도는
\(Worst(n) = n\)이 되는 것이다.
또한 평균 복잡도를 알기 위하여 다음과 같이 나타낼 수도 있다. 찾고자하는 값 x가 리스트 lst에
골고루 분포해있고 x가 k번째에 있다고 가정하면 k번 비교해야 하므로 평균적인 시간 복잡도는
다음과 같다.
이처럼 순차 탐색은 입력 사례에 따라서 시간 복잡도가 달라진다. 따라서 알고리즘의 시간 복잡도를 단 하나의 함수로 표현할 수 없고, 최선・최악・평균 시간 복잡도가 따로 존재한다.
빅오 표기법(Big-O Notation)
빅오는 복잡도 함수의 점근적 상한 표기법으로 같은 점근적 표기법으로는 하한을 나타내는 빅오메가(Ω), 빅세타(Θ)도 있는데 이러한 점근적 표기법이 왜 필요한지 먼저 알 필요가 있다.
어떤 알고리즘이 빠른 알고리즘인가?
시간 복잡도가 \(f_1(n) = n\)인 알고리즘 \(f_1\)과 \(f_2 = n^2\)인 알고리즘 \(f_2\)가 있다.
입력값이 각각 \(f_1\)은 \(1000t\), \(f_2\)은 \(t\)인 경우, \(f_1\)은 \(f_2\)보다 1000배나 느리다. 하지만 \(n\)이 1000을 넘어가는 순간. 즉, \(n\)이 1000보다 큰 모든 경우 \(f_1\)이 \(f_2\)보다 빠르기 때문에 궁극적으로 \(f_1\)이 \(f_2\)보다 빠르다고 할 수 있다. 이를 통해 1차식의 알고리즘이 2차식의 알고리즘보다 빠른 것을 알 수 있다.
이와 같이 알고리즘의 시간 복잡도는 차수(Order)로 성능을 분류할 수 있으며 차수가 낮은 알고리즘이 차수가 높은 알고리즘보다 빠르다고 할 수 있다.
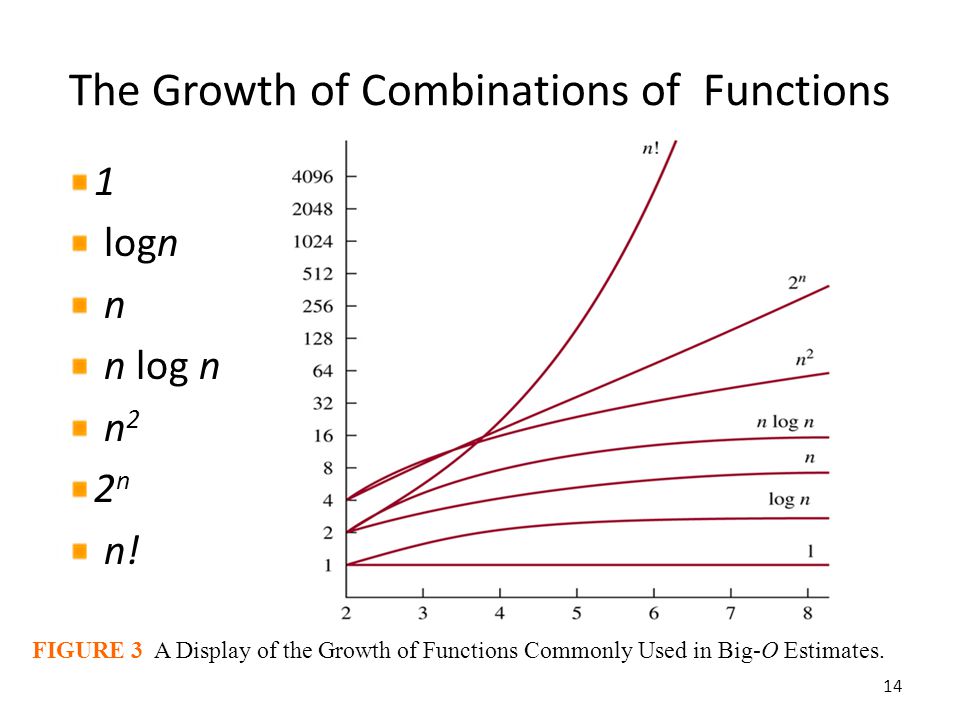
이처럼 최고 차항이 알고리즘의 궁극적인 성능을 결정하는데 가장 중요한 요소이기 떄문에 복잡도를 분류할 때 낮은 차항의 차수는 버려서 추상화할 수 있다. 이것을 표현하기 위한 방법이 점근적 표기법(Asymptotic notation)이다.
빅오(\(O\))
알고리즘 복잡도의 점근적 상한(Upper bound)이다. 아무리 적어도 이 이상은 넘지 않는다는 것을 의미한다. 최악의 경우에 대한 최소한의 성능을 보장하기 때문에 보통 시간 복잡도라고 하면 빅오(\(O\))를 의미하는 경우가 많다.
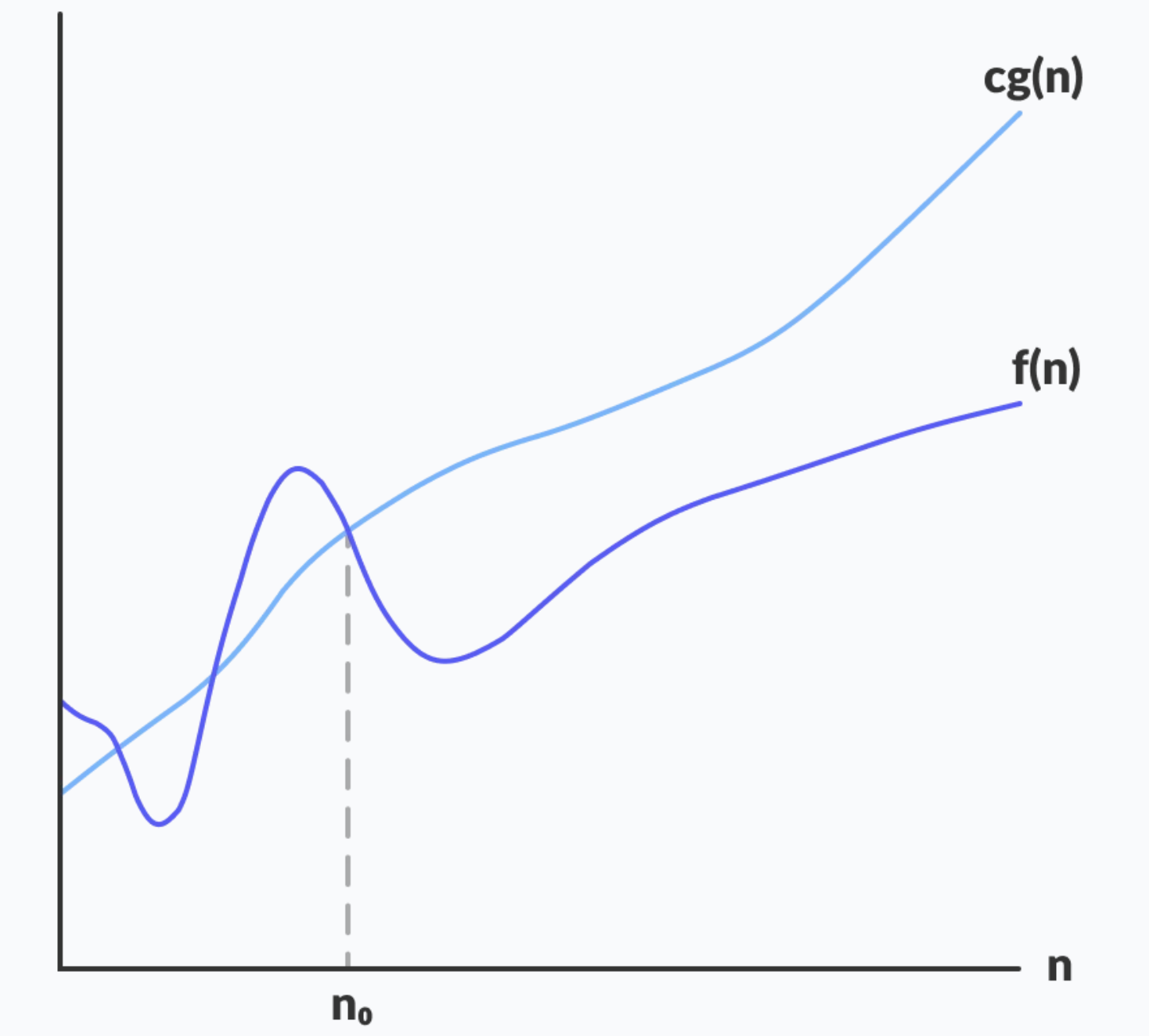
시간 복잡도를 빅오(\(O\))로 표현할 때 최고 차항의 차수(Order)만 표시하고 계수는 무시한다.
예를 들어 입력값 \(n\)에 대하여 \(103n^2 + 29n + 11\)만큼 계산하는 알고리즘이 있다면 이 알고리즘의 시간 복잡도는 최고 차항인 \(103n^2\)만 고려한다. 다시 여기서 계수를 무시하며 \(n^2\)만을 고려한다. 따라서 이 알고리즘의 시간 복잡도(상한)는 \(O(n^2)\)이 된다.
다음은 알고리즘 실행 시간의 추이에 따른 빅오 표기법에 대한 설명이다.
- \(O(1)\): 상수 시간 알고리즘으로 입력 크기가 아무리 커도 실행 시간이 일정한 알고리즘이다. 최적의 알고리즘이지만 아무리 상수 시간에 수행되는 알고리즘이라고 하더라도 상수 값이 천문학적인 숫자일 정도로 크다면 의미가 없다. 따라서 적용에 신중해야 한다. \(O(1)\)에 실행되는 알고리즘으로는 해시 테이블(Python’s Dictionary)이 있다.
- \(O(log\ n)\): 여기서부터 입력 값에 실행 시간이 영향을 받지만 웬만한 크기에 대해서는 견고하다. 이진 탐색 알고리즘이 이에 해당하며, 술자리에서 하는 Up & Down 게임의 원리와 같다.
- \(O(n)\): 알고리즘을 수행하는 데 걸리는 시간이 입력 값에 비례한다. 선형 시간(Linear-time) 알고리즘이라고 한다. 정렬되지 않은 리스트에서 최댓값 or 최솟값을 찾는 경우가 이에 해당한다.
- \(O(n\ log\ n)\): 병합 정렬(merge sort)을 비롯한 대부분의 효율 좋은 정렬 알고리즘이 이에 해당한다. 모든 수에 대해서 한 번 이상(n번) 비교해야 하므로 비교 기반 정렬 알고리즘의 복잡도는 \(O(n\ log\ n)\)보다 빨라질 수 없다.
- \(O(n^2)\): 버블 정렬처럼 비효율적인 알고리즘이 이에 해당한다.
- \(O(2^n)\): 피보나치 수를 재귀 호출로 계산[3]하는 알고리즘이 이에 해당한다. \(O(n^2)\)와 혼동할 수 있는데 \(n\)에 10을 대입해서 계산해보면 \(2^n\)이 훨씬 크다는 것을 쉽게 알 수 있다.
- \(O(n!)\): 가장 느린 알고리즘이다. 파이썬으로 \(100!\) 정도만 계산해봐도 답이 바로 안 나오는 것을 확인할 수 있다. 각 도시를 방문하고 돌아오는 가장 짧은 경로를 찾는 외판원 문제(Traveling salesman problem)를 단순 무식한 브루트 포스(Brute force)로 풀이하는 경우에 해당한다.
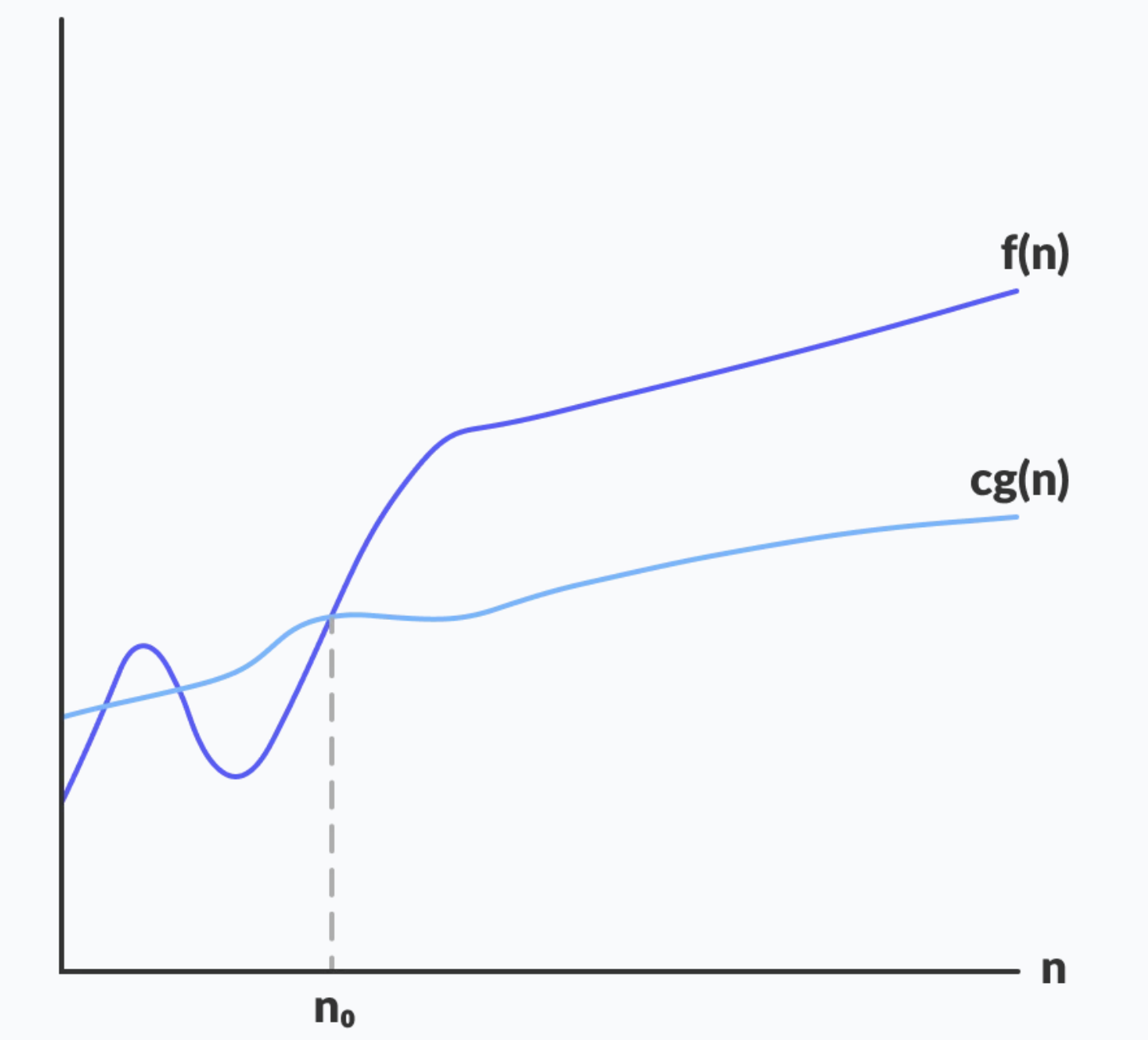
빅오메가(Ω)
알고리즘 복잡도의 점근적 하한(Lower bound)이다. 최상의 시나리오를 설명하며 적어도 이보다 짧은 시간에 수행할 수 없다는 것을 의미한다. 알고리즘 수행시간의 최소 시간을 설명할 때 사용한다.
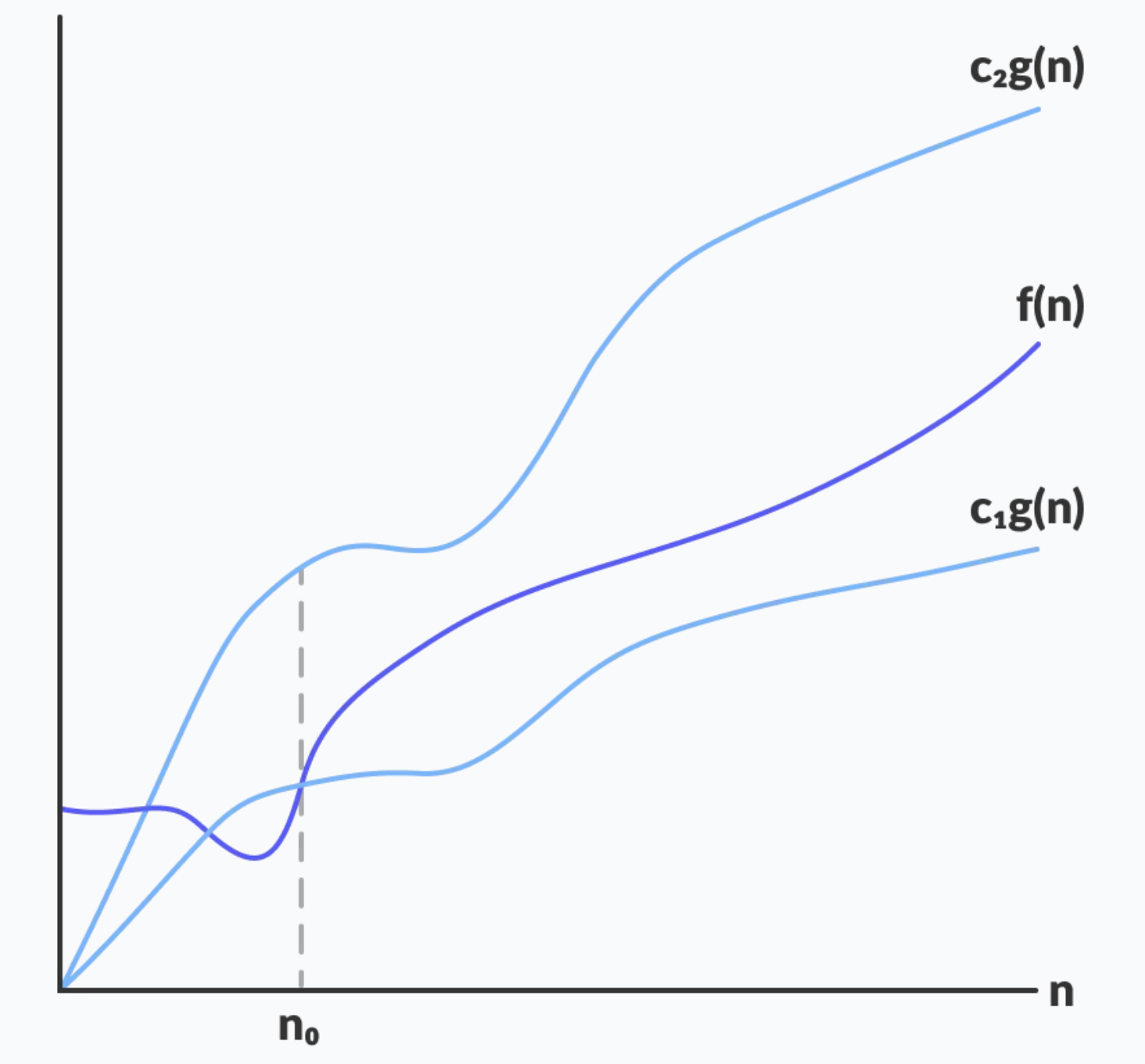
빅세타(Θ)
복잡도 함수의 상한과 하한을 모두 설명한다. 상한과 하한을 모두 나타내므로 알고리즘의 평균 복잡도를 분석하는데 활용한다. 여기서 가장 늦게 실행될 때가 빅오(O), 가장 빨리 실행될 때가 빅오메가(Ω)이다.
각주
1 : 모든 입력 사례에 대해 정확한 답을 찾는다는 것을 증명하는 것
2 : 입력 크기가 커지는 정도에 따라 성능의 변화량을 증명하는 것
3 : 재귀 호출하지 않고 변수를 할당하여 공간 복잡도를 희생하여 계산하면 성능이 향상된다.
댓글남기기